1. Ein LLM auswählen
Mit Domino selbst werden keine Sprachmodelle ausgeliefert, weshalb Ihre erste Aufgabe darin besteht, sich ein passendes Modell zu besorgen. Das klingt schwieriger als es ist, LLMs werden im Internet auf zahlreichen Webseiten wie etwa ollama.com oder hugging-face.co angeboten. Viele LLMs können gratis genutzt werden, doch Vorsicht, auch bei Open-Source gibt es unterschiedliche Lizenztypen, manche erlauben einen uneingeschränkten kommerziellen Gebrauch, andere sind nur zur privaten Nutzung oder zu Forschungszwecken freigegeben. Unter welchen Lizenztyp Ihr gewünschtes LLM fällt, ist meist genau angegeben.
Bedenken Sie auch, dass LLMs immer nur bis zu einem bestimmten Stichtag trainiert wurden, was zumindest beim Abfragen von Fachwissen eine Rolle spielt.
LLM-Dateien werden in unterschiedlichen Formaten angeboten, der Domino IQ-Server unterstützt ausschließlich LLMs im GGUF-Binärformat. Als Einstieg empfehle ich die Webseite huggingface.co. Mithilfe der folgenden URL können Sie Ihre Suche auf das GGUF-Format einschränken:
https://huggingface.co/models?library=gguf
Beginnen Sie mit den Modellen aus der Llama-3.x-Familie und setzten Sie einen Filter auf »llama-3.2« oder »llama-3.3«. Hier gibt es immer noch eine größere Auswahl und wenn Sie nicht wissen, welches Sie nehmen sollen, probieren Sie zuerst das Community Model:
https://huggingface.co/lmstudio-community/Llama-3.2-3B-Instruct-GGUF
Laden Sie das LLM herunter und kopieren Sie die Datei ins Verzeichnis:
\llm_models
Alternativ können Sie Domino IQ auch anweisen, die Datei für Sie herunterzuladen – darüber später mehr.
In Version 14.5 kann jeder Domino-IQ-Server nur ein einziges LLM verwalten, Sie können Domino-IQ jedoch auf mehreren Domino-Servern aktivieren und so mehrere LLMs mit unterschiedlichen Spezialisierungen zum Abfragen zur Verfügung stellen.
2. Ein LLM-Dokument erstellen
Beginnen Sie mit der Anlage eines LLM-Dokuments. Dazu müssen Sie die GGUF-Datei entweder bereits heruntergeladen und im Verzeichnis \llm_models abgelegt haben oder Sie beauftragen Domino IQ, dies für Sie zu tun.
Um ein LLM-Dokument zu erstellen, gehen Sie wie folgt vor:
- Öffnen Sie die Anwendung »Domino IQ Configuration« (dominoiq.nsf).
- Wechseln Sie zur Ansicht Models und klicken Sie auf die Schaltfläche Add Model. Das Dokument »LLM Model« wird erstellt.
- Geben Sie im Feld Model name einen Namen für das LLM ein. In meinem Beispiel habe ich das Modell Llama-3.2-3B-Instruct-Q8 von Meta ausgewählt.
- Geben Sie im Feld Description eine beliebige Beschreibung ein.
- Geben Sie im Feld File name den exakten Dateinamen der GGUF-Datei an.
- Wenn Sie die Datei bereits ins Verzeichnis llm_models kopiert haben, lassen Sie die Einstellung im Feld Download model auf »Disabled«.
Alternativ können Sie das LLM auch von Domino IQ herunterladen lassen. Wählen Sie dazu im Feld Download model die Option »Enabled« und geben Sie die Download-URL sowie – falls erforderlich – den SH-256-Hash ein.
Der Domino-IQ-Task prüft alle 5 Minuten, ob Modelle verfügbar sind. Findet er ein neu erstelltes Modell mit aktiviertem Download, lädt er es herunter und legt es im Verzeichnis llm_models ab. Das Herunterladen kann abhängig von der Größe des LLMs lange dauern. - Speichern und schließen Sie das Dokument.
Um das LLM zu aktivieren:
- Öffnen Sie das Dokument erneut und schalten Sie in den Bearbeitungsmodus um.
- Klicken Sie auf die Schaltfläche Modify Model Status.
- Bestätigen Sie die Sicherheitsfrage mit »Ja«:
- Der Status des Modells ist jetzt »Model available«.
- Speichern und schließen Sie das Dokument.
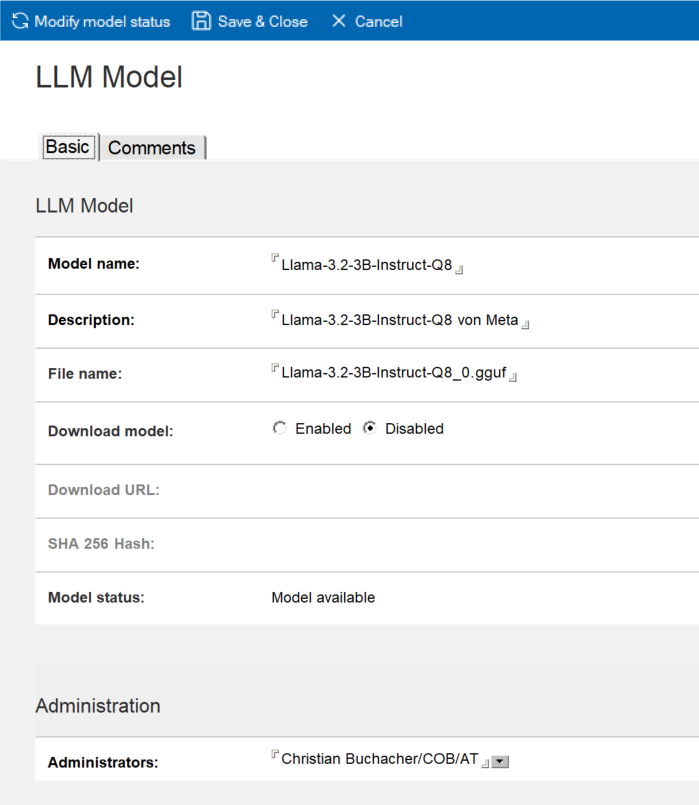
Abbildung 1: Dokument »LLM Model«
3. Ein Konfigurationsdokument erstellen
Im nächsten Schritt müssen Sie eine Konfiguration erstellen. Gehen Sie dazu wie folgt vor:
- Wechseln Sie zur Ansicht Configurations und klicken Sie auf die Schaltfläche Add Configuaration. Das Dokument »Domino IQ Configuration« wird angezeigt.
- Wählen Sie im Feld AI endpoint mode »Local«, um ein lokal im Verzeichnis »llm_models« gespeichertes LLM zu verwenden.
Erinnerung: Für ein lokal angebundenes LLM muss eine CUDA-fähige NVIDIA-GPU vorhanden sein! - Geben Sie im Feld Domino server name den Namen des Domino IQ-Servers an, für den Sie die Konfiguration erstellen. Sie können den Namen auch mithilfe der Taste Servers aus-wählen.
- Wählen Sie im Feld Model das Modell aus dem zuvor erstellten Dokument aus. (Es muss bereits den Status »Model available« aufweisen, sonst erscheint es nicht in der Liste.)
- Setzen Sie das Feld Status auf »Enabled«.
- Optional: Ändern Sie die Portnummer für den AI-Inferenzserver, der später als »localhost« auf dem Domino IQ-Server ausgeführt wird. Ohne TLS ist die Vorgabe 8080 und mit TLS 8443. TLS wird für die lokale Kommunikation nicht benötigt und ich würde einmal ohne starten. (Die Konfiguration von TLS erkläre ich im 4. Teil.)
- Optional: Wechseln Sie zum Reiter Advanced. Zu den Einstellungen auf dieser Seite gibt es wenig Informationen, weshalb Sie diese besser nicht verändern – außer Sie wissen genau, was Sie tun! Nachfolgend ein paar Hinweise:
Number of concurrent requests: Anzahl der Anfragen, die gleichzeitige ans LLM ge-schickt werden dürfen.
GPU offloading: Ist eine Methode zum Verschieben eines Modells oder Teilen eines Modells (Layers) zwischen dem GPU-Speicher (VRAM) und dem Systemspeicher (RAM), um die Ausführung auf GPUs mit wenig VRAM zu ermöglichen. Passt das LLM ganz in den VRAM der GPU, ist kein GPU-Offloading notwendig.
Die Temperature ist eine Kommazahl zwischen 0,0 und 1,0, welche die Balance zwischen Genauigkeit und Kreativität bei KI-Ausgaben bestimmt. Hohe Temperatureinstellungen sind in generativen Sprachmodellen für kreatives Schreiben und künstlerische KI-Anwendungen nötig, führen bei sachlichen Themen aber häufiger zum sogenannten »Halluzinieren«. Entsprechend sind in Anwendungen, die Genauigkeit erfordern, wie maschinelle Übersetzung und Datenanalyse, niedrigere Temperaturen vorzunehmen. Typische Temperatureinstellungen wären 0,0 – 0,3 für Datenanalyse bzw. 0,7 – 0,9 für Kreatives Schreiben. Geben Sie nichts ein, wird der Wert 0,0 übergeben.
Das Feld Special parameters kann dazu verwendet werden, extra Optionen an den llama-Server zu übergeben. Welche das sein könnten, ist mir unbekannt. - Speichern und schließen Sie das Dokument.
- Starten Sie den Domino-Server neu.
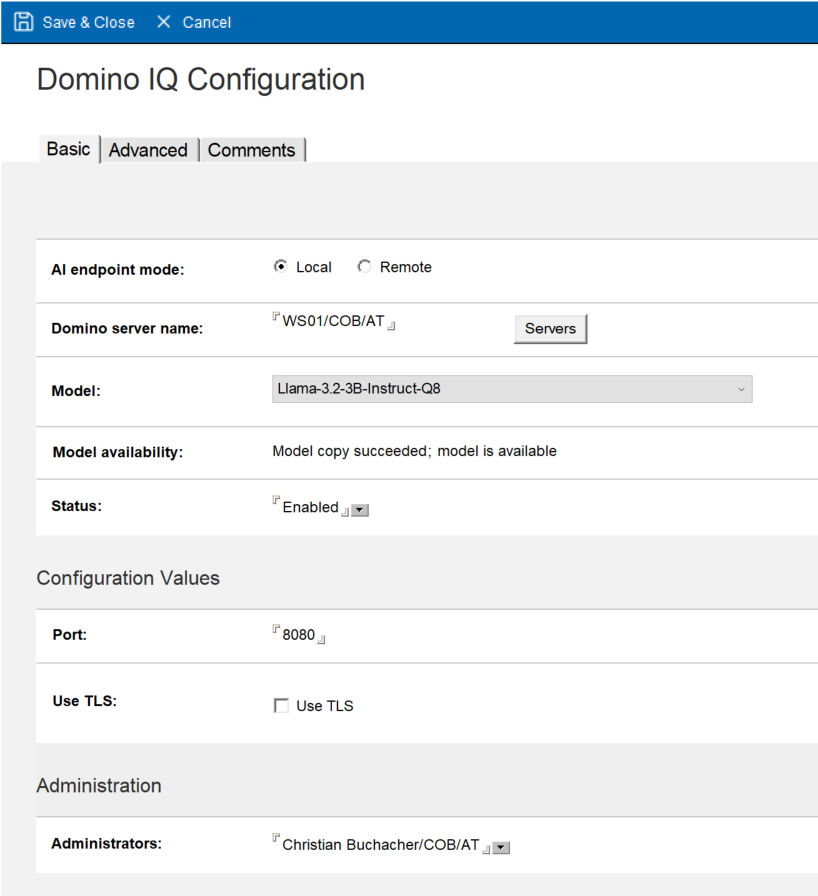
Abbildung 2: Dokument »Domino IQ Configuration«
Beim Hochfahren des Servers sollten Sie folgende Meldung auf der Konsole sehen:
28.07.2025 22:36:23 DominoIQTask: AI-Engine läuft, Modell geladen = Llama-3.2-3B-Instruct-Q3_K_L.gguf
Und nach Eingabe des Befehls show tasks folgenden Eintrag in der Liste der Datenbankserver vorfinden:
Database Server DominoIQ: Wird ausgeführt: Modell – Llama-3.2-3B-Instr
Ist jedoch ein Fehler aufgetreten, finden Sie auf der Serverkonsole:
28.07.2025 22:12:09 DominoIQTask: Die Domino IQ-KI-Engine wurde unerwartet beendet.
Und in der Liste der Servertasks steht dann:
Database Server DominoIQ: Standby – Fehler
4. Die Protokollierung hochdrehen
Standardmäßig schreibt Domino IQ in die Protokolldatei dominoiq_server.log im Unterverzeichnis IBM_TECHNICAL_SUPPORT. Und wenn ein Fehler auftritt, werden Sie mit etwas Glück auch darin fündig. So trat bei mir gleich beim ersten Hochfahren ein Fehler auf und ich im Protokoll den benötigen Hinweis finden:main: couldn't bind HTTP server socket, hostname: 127.0.0.1, port: 8080
Ein anderes Programm verwendete bereits den Port 8080. Dieses war schnell gefunden: ein Service namens webPDF, von dem ich mich erinnern kann, ihn jemals installiert zu haben …
Leider reicht das Standardprotokoll nicht immer aus, um alle Fehler aufzuspüren. Sie können den Domino IQ-Server aber zu größerer Gesprächigkeit überreden – mit folgenden Einträgen in der Datei notes.ini:
DEBUG_DOMIQ=1
Damit erfolgt eine ausführlichere Ausgabe auf der Serverkonsole.
DEBUG_DOMINOIQ_LLMREQUEST=1
Damit wird auch die Protokollierung der Antworten des AI-Servers auf der Konsole ausgegeben.
DEBUG_DOMINOIQ_LLMPAYLOAD=1
Damit erfolgt eine detaillierte Verbindungs-, Anfrage- und Antwortverfolgung im Verzeichnis IBM_TECHNICAL_SUPPORT. Pro Anfrage wird nach folgendem Muster eine eigene Datei erstellt:
domiqllmthr-{Nummer}{Servername}{Datum@Zeit}
5. Das LLM abfragen
Wenn bei Ihnen kein Fehler auftrat bzw. Sie ihn beheben konnten, ist es jetzt an der Zeit, die KI etwas zu fragen. Das ist über die beiden in der Maildatenbank ausgelieferten KI-Aktionen ohne weitere Konfiguration möglich. Suchen Sie sich also eine Mail im Posteingang, öffnen Sie diese (das Vorschaufenster reicht dazu nicht) und wählen Sie im Untermenü der Schaltfläche Antworten die Option Domino IQ Nur mit Verlaufsprotokoll antworten:
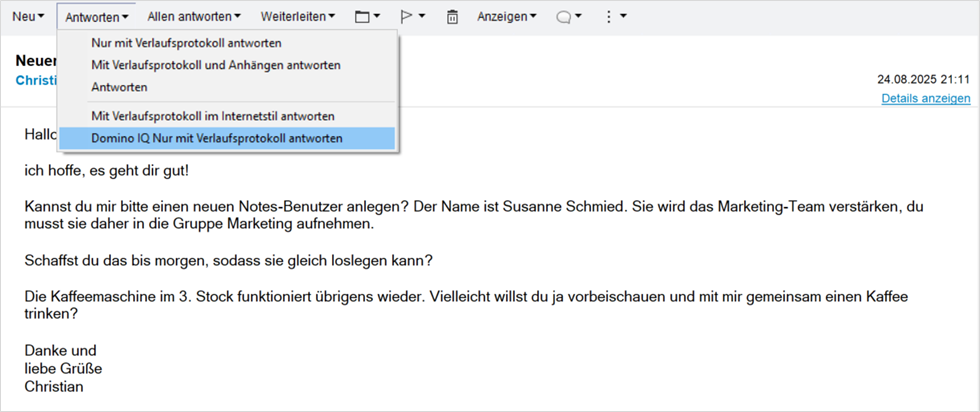
Abbildung 3: Aktionsschaltfläche »Domino IQ Nur mit Verlaufsprotokoll antworten«
Wenn alles funktioniert, erstellt die KI innerhalb weniger Sekunden eine Antwort ähnlich der Folgenden:

Abbildung 4: Die Antwort der KI
Wie brauchbar die Antwort ist, sei einmal dahingestellt. Prinzipiell gilt die Regel: Je exakter die Frage, umso besser auch die Antwort. Zumindest sparen Sie sich einiges an Tipparbeit.
Sollten sie stattdessen eine Fehlermeldung erhalten, ist womöglich die Paraphrasierung schuld.
6. Paraphrasierung
Per Vorgabe verwendet Domino IQ eine sogenannte Paraphrasierung (Paraphrasing). Damit soll verhindert werden, dass das LLM andere Operationen ausführt als vorgesehen. Leider wird durch diese Funktion die Eingabe häufig so stark verändert, dass die KI andere Ergebnisse liefert als gewünscht. Und es gibt auch einen Bug, der bei aktivierter Paraphrasierung und deutschen Umlauten eine Fehlermeldung generiert:
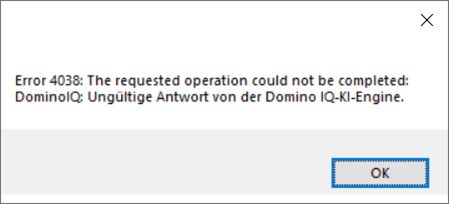
Abbildung 5: Domino IQ, Beispiel für Fehlermeldung
Dieser Bug wurde mit 14.5 FP1 gefixt. Natürlich hätte es auch sein können, dass das von Ihnen gewählte LLM Deutsch nicht unterstützt und mit den deutschen Sonderzeichen nicht klarkommt. Das ist beim Modell Llama 3.x jedoch nicht der Fall, es unterstützt gleich mehrere Sprachen, darunter auch Deutsch. Obige Fehlermeldung ist also der Paraphrasierung anzulasten.
Ich empfehle Ihnen, die Paraphrasierung in Version 14.5 in jedem Fall abzuschalten. Fügen Sie dazu den folgenden Eintrag zur Datei notes.ini des IQ-Servers hinzu und starten Sie ihn neu:
DOMIQ_DISABLE_PROMPT_PARAPHRASE=1
Im vierten Teil unserer Serie zeige ich Ihnen, wie Sie Domino IQ mit einem entfernten (remote) LLM verbinden.